Breakthrough or illusion? Scientists announce new way to improve AI
 Researchers have found a possible way to scale AI without additional training (photo: Freepik)
Researchers have found a possible way to scale AI without additional training (photo: Freepik)
Recently, researchers presented one of the new laws of scaling, which, according to them, can significantly improve AI. However, despite loud statements, experts are skeptical about the real effectiveness of this approach, reports TechCrunch.
How can AI scaling laws change the industry
AI scaling laws are an informal concept that describes how the performance of AI models improves as the size of training datasets and computing power increases.
Until last year, the dominant approach was pre-learning scaling, which is the creation of extended models that learn on ever larger amounts of data. This principle has been applied by most leading AI labs.
Although pre-training is still relevant, two additional scaling laws have emerged:
- Post-training scaling - adjusting model behavior after the main training phase
- Runtime scaling is the use of additional computations while the model is running to enhance its "logical" abilities.
Recently, researchers from Google and the University of California, Berkeley, proposed what some commentators have called the fourth law of inference-time search.
What is inference-time search and how does it work
This method allows the model to generate many possible answers to a query at once and then select the best one among them.
Researchers claim that this approach can improve the performance of outdated models. For example, Google Gemini 1.5 Pro allegedly outperformed the OpenAI o1-preview model in math and science tests.
"By simply picking a random 200 answers and checking them on our own, Gemini 1.5, an ancient AI model by early 2024 standards, bypasses o1-preview and gets closer to o1," one of the study's authors, Google PhD scholar Eric Zhao, wrote on Twitter.
He also noted that "self-checking" becomes easier as you scale up. Intuitively, it seems that the more solutions the model considers, the more difficult it is to choose the right one, but in practice, the opposite is true.
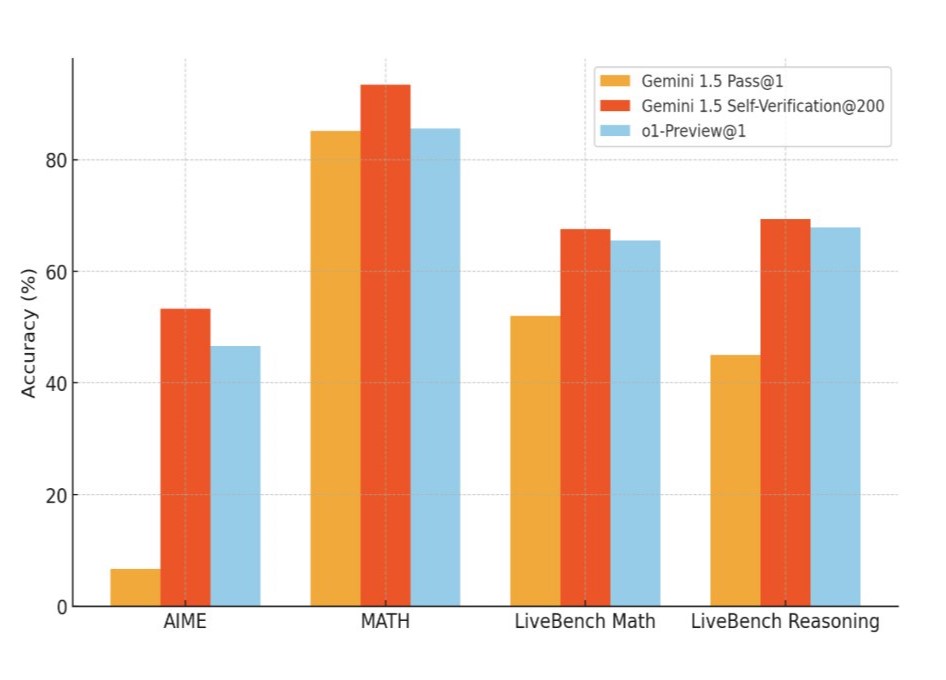
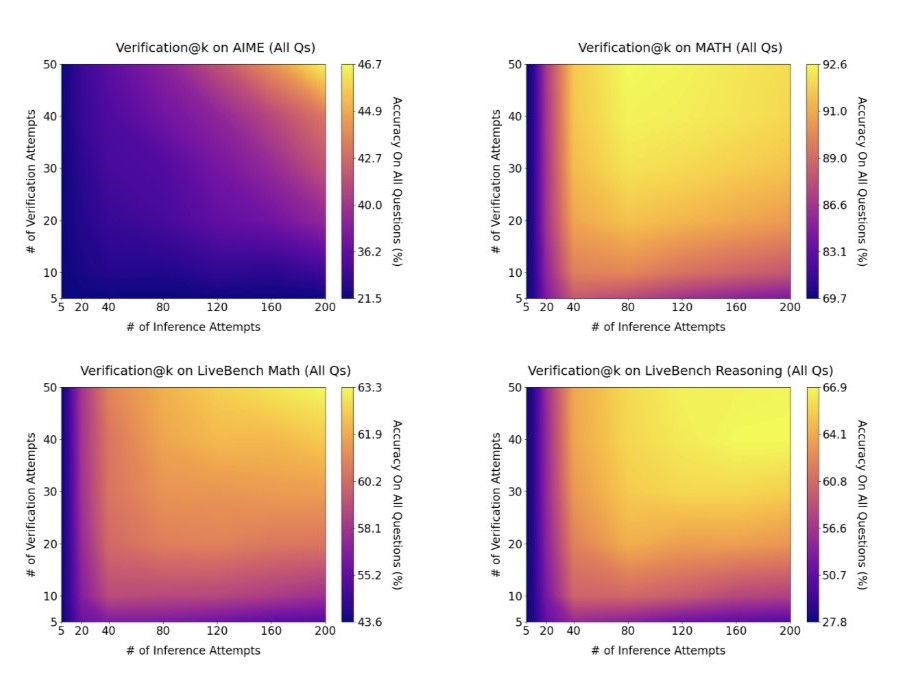
Gemini 1.5, an earlier model, outperforms o1-Preview and comes close to o1 after selecting and checking 200 answers (photo: X/@ericzhao28)
Doubts from experts
Despite such statements, a number of researchers believe that the runtime search method is not universal and mostly useless.
According to Matthew Guzdial, an AI researcher and assistant professor at the University of Alberta, this method is effective only when it is possible to clearly determine which answer is the best.
"If we can't program clear criteria for the correct answer, then runtime search is useless. It doesn't work for normal interaction with a language model. This is not the best approach for solving most problems," he said.
Mike Cook, a research fellow at King's College London, agrees. He emphasized that this method does not improve the process of logical inference in the model, but only helps to circumvent its limitations.
"Runtime search does not make the model smarter. It's just a way to get around the shortcomings of technologies that can make mistakes, but to do so with complete confidence. It is logical that if the model is wrong in 5% of cases, then by checking 200 solution attempts, we will notice the errors faster," Cook said.
AI industry in search of new scaling methods
The limitations of the runtime search method are unlikely to please the AI industry, which seeks to improve the logical abilities of models with minimal computing power.
According to the researchers, modern models focused on "logical thinking" can spend thousands of dollars of computing resources to solve a single mathematical problem.
The search for new scaling methods is still ongoing.
You may also be interested in:
- The main myths about AI that millions of people still believe in
- How AI will revolutionize the gaming industry in the coming years

